Lenka Skalická, Petra Sučková
Na začátku bylo jedno nečekané, ale zato milé setkání na první hodině. Setkání po asi 9 letech od ukončení gymplu. Po druhé lekci jsme se na pivu domluvily, že do projektu půjdeme spolu. A teď vymyslet téma. Paradoxně pro nás asi to nejtěžší z celého kurzu :D Projely jsme minulé projekty pro inspiraci, volně dostupné datasety, ale furt to nebylo to “pravý vořechový”. Nakonec, jak to tak někdy bývá, k nám téma přišlo samo a společně s ním i náš mentor Pavel.
Pavel nám na Meet Your Mentor navrhnul pracovat s jeho daty o výsledcích nějaké online hry (v té době nám název nic neříkal, natož abychom si to zapamatovaly :D), predikovat výsledky a následně to porovnávat s kurzy sázkovek a případně i sázet. Znělo nám to maličko nelegálně a o to víc se nám to líbilo :)
Než se přesuneme k samotné naší práci, je nutné si něco říct o "té" online hře. Jmenuje se League od Legends, ale všichni jí říkají LoL. Cílem hry je dobýt území protihráče a zničit mu pevnost. Každý tým je tvořen 5 hráči. Hráč nebo celý tým sbírá kredity (goldy) na vybavení v rámci jedné hry. Na začátku dostane hráč určitý počet goldů a další může získat zabitím MPC (samochodící postavičky) nebo protihráčů. Čím více má hráč goldů, tím lepší může mít vybavení a tím větší má šanci porazit soupeře.

Zdroj: http://matpat.wikia.com/wiki/League_of_Legends
Zdroj: http://matpat.wikia.com/wiki/League_of_Legends
Tak téma bychom už měly a směle do toho. Prvním krokem bylo získat data od Pavla a jejich nahrání do databáze. Jako databázi jsme použily PostgreSQL. Dataset obsahuje 4 tabulky (game_results, player_teams, team_matches, teams), ale o tom si povíme více dále u datového modelu.
A teď vymyslet, co se dá s těmi daty všechno dělat a jaký bude další postup. Po první schůzce s Pavlem jsme měly více jasno. Vyšly nám 3 cesty, co dál (přesný přepis z poschůzkové mailové komunikace):
- Obohacení algoritmu o data o hráčích. Obnáší stažení (scrape) dat z webu, jejich propojení s aktuálními daty a následná evaluace. Zkusíme: python (stažení dat), uložení a načtení dat z DB, pandas merge dat.
- Identifikace vazeb mezi proměnnými a výherností. Jde v podstatě o to udělat korelační analýzu, třeba dál Principle Component Analysis. Udělat nějaký graf, redukovaná/obohacená data vložit do aktuálního či jiného algoritmu. Zkusíme: python, pandas, sklearn, matplotlib + seaborn(grafy)
- Update Machine Learning. Zkusíme: python+scikitlearn, deep learning framework
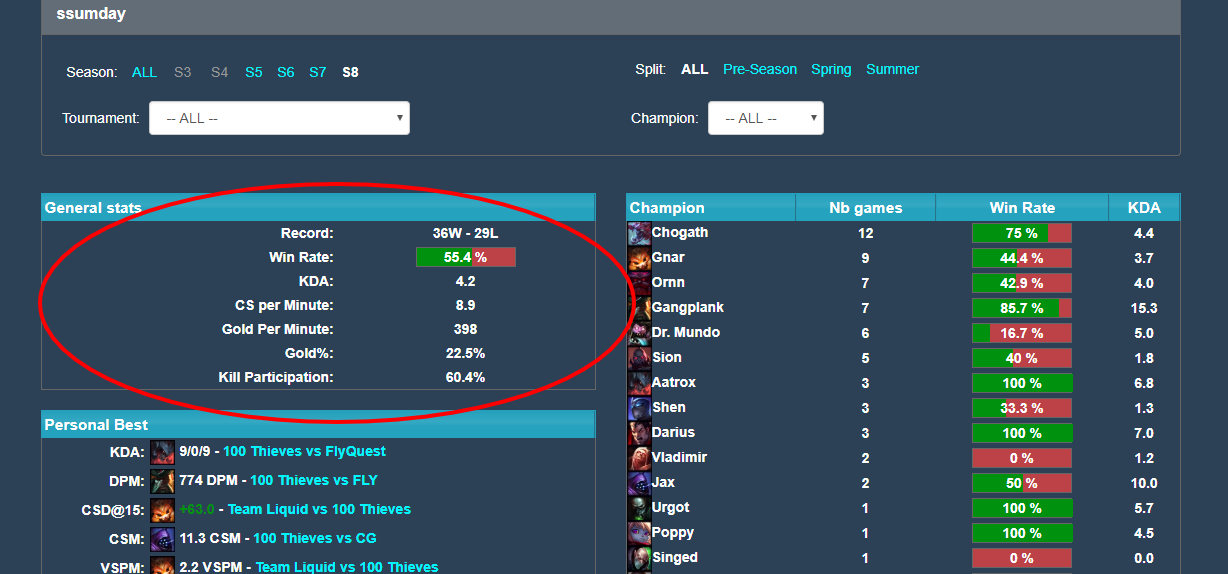
Zdroj:http://gol.gg/players/player-stats/107/season-S8/split-ALL/tournament-ALL/champion-ALL/


Data jsme stahovaly přes Python. Pomocí knihovny Requests jsme se dotazovaly na webové stránky a pomocí Pandas jsme ze stránky vybraly tabulku s daty, která jsme následně stáhly do nově vytvořené tabulky v již existující databázi v PostgreSQL. V rámci stahování jsme také data upravily, ať už se týče změny datového typu nebo odstranění znaků (např.%). Celý kód můžete vidět výše.
Celý proces stahování dat zabral pár hodin a naštěstí proběhlo bez chyb (uuuffffffff :) ). Výsledkem byla v PostgreSQL nová tabulka players_statistics, která obsahovala pro každého hráče údaje o počtu výher a proher, míru úspěšnosti, KDA (Kill Death Assist = součet počtu zabití a asistencí vydělený počtem smrtí hráče, CS za minutu, Gold za minutu, Gold (v %) a spoluúčast na zabití.

Chtěly jsme se podívat trošku na kloub datům, odpovědět si na otázky, které jsme si předem stanovily a k tomu nám nejlépe posloužilo Power BI (když už jsme nad tím strávily na hodinách tolik času, tak to prostě musíme použít :D ). Byť byl tento program pro nás na začátku nejméně zajímavý, tak jsme v průběhu běhu změnily názor (díky, Adélko! :) ). Data jsme chtěly nahrát do Power BI přes PostgreSQL databázi, ale protože byl problém se na databázi připojit, tak nastal plán B - všechny tabulky jsme stáhly do formátu csv a následně nahrály do Power BI. Nejprve jsme se podívaly blíže na datový model a ověřily si, že nám Power BI správně tabulky propojilo. Data obsahují informace o výsledcích ze 4 sezón v rámci celého světa, což dělá 3018 zápasů.

Pěknou chvilku nám také zabraly úpravy a kontrola dat v query editoru - změny datových typů, přejmenování a sjednocení regionů a jejich následné seskupování, rozdělování sloupečků, nové metriky a sloupečky a další.
A co jsme se tedy z dat dozvěděly a jak jsme si na předem stanovené otázky odpověděly?
- Který tým je nejúspěšnější?

Pozn. Počet zápasů je větší než 50.
Nejvyšší win rate (procentuální vyjádření poměru vítězných zápasů k celkovému počtu zápasů) přes 80% vykazují dva týmy - Flash Wolves z Taiwanu a SKTelecom T1 z Jižní Korei.
- Který hráč je nejúspěšnější?

Pozn. Počet zápasů je větší než 50.
Nejvyšší win rate má hráč TheShy z týmu Invictus Gaming z Číny a to necelých 85%. Dalších 10 míst patří hráčům již zmíněných týmů Flash Wolves a SK Telecom T1.
- Jaké je zastoupení týmů v rámci rozdělení regionů? Ve kterém regionu jsou nejúspěšnější týmy?
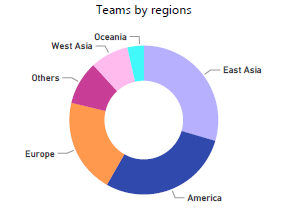

Nejvíce týmů je v regionu východní Asie (Čína, Japonsko, Taiwan, Jižní Korea, Vietnam) a to 75 týmů, následuje Amerika (Severní a Jižní Amerika) se 73 týmy a dále s 52 týmy Evropa. I nejvyšší win rate má region východní Asie (53,78%), za kterým je Evropa (51,73%) a Amerika (50,23%). Nicméně nutno říct, že v dalších dvou regionech - Oceánie a západní Asie, není win rate o moc nižší (49,80% a 49,59%).
Po analýze v Power BI byla před námi další meta - slavný a obávaný Machine Learning (finally :D ) Další analýza tedy probíhala pomocí Pythonu a základů Machine Learning. S pomocí našeho mentora Pavla bylo rozhodnuto aplikovat binární logistickou regresi. Nejprve jsme data rozdělily a pracovaly jen s 80% dat, na kterých jsme trénovaly. Zbylých 20% mělo sloužit ke kontrole funkčnosti algoritmu. Jak už bylo zmíněno výše, použily jsme knihovny jako Pandas, Seaborn, Sklearn nebo Matplotlib. S daty jsme si trochu pohrávaly. Naformátovaly jsme data tak, že jsme měly každý tým zvlášť na jednom řádku nebo na jednom řádku údaje týmu a jejich protihráče. Dalším krokem byla korelace a vytvoření korelačního grafu. Tím jsme se snažily zjistit, které aspekty mají největší vliv na výhru. Ty, co byly mimo kolerační rozsah -2 a 2, jsme vymazaly, protože ovlivňují výhru nejméně.
Dále jsme provedly analýzu v rámci jednoho týmu a vytvořily listy statistik hlavního týmu a listy statistik druhého týmu, které jsme mezi sebou porovnávaly. Nakonec jsme rozdělily dataset na testovací a trénovací množiny, definovaly ML model a jeho ohodnocení. Výsledkem je predikce výhry jednoho zápasu.


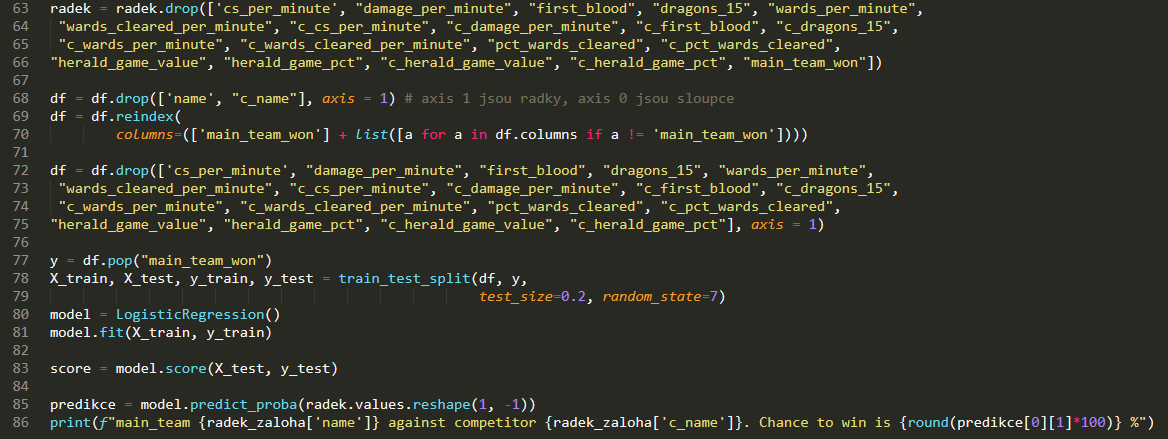
Potom, co jsme si to vyzkoušely na předem daných týmech, tak jsme se rozhodly vytvořit command line aplikaci, ve které si “uživatel” bude moci přímo zadat dva konkrétní týmy, pro které chce zjistit pravděpodobnost výhry při hře jednoho týmu proti druhému.


Po zadání názvů prvního a druhého týmu se nám zobrazí s jakou pravděpodobností vyhraje první tým (jak můžete vidět na obrázku výše).
Huráááá, máme hotovo a teď už můžeme jenom sázet :)
{kind=link}

Zdroj: http://www.memesboy.com/19-funny-money-meme-that-give-you-expensive-smile/
K naší smůle se aktuálně nehrály žádné zápasy. Po krátkém zamyšlení a pátrání jsme dospěly k závěru, že naši aplikaci vyzkoušíme na již proběhlé zápasy a to rovnou na zápasy v rámci mistrovství světa konaném v Jižní Korei letos v říjnu.

Zdroj: https://www.dexerto.com/league-of-legends/the-groups-have-been-drawn-for-the-2018-league-of-legends-world-championship-171622
Jaký je systém mistrovství světa? Mistrovství se účastní celkem 24 týmů. Některé týmy jsou do hlavní soutěže poslány rovnou a některé si musí projít kvalifikací. My se podíváme přímo na výsledky hlavní soutěže, kde byly týmy rozděleny do 4 skupin (GROUP A, B, C, D) po 4 týmech, každý hrál s každým. Ze skupin vždy 2 nejlepší týmy prošly do čtvrtfinále (8 nejlepších týmů), následovalo semifinále a nakonec finále.
Budeme porovnávat naši predikci výsledku zápasu (pravděpodobnost výhry hlavního týmu) se skutečným výsledkem zápasu. Nejde primárně o to, abychom u každého zápasu určily, kdo bude podle naší aplikace vítěz a na koho bychom vsadily, ale chceme porovnat naši pravděpodobnost výhry hlavního týmu s realitou a rozhodnout, zda je to validní či nikoliv. Bohužel do toho nemůžeme zahrnout predikci (kurzy) sázkových kanceláří, protože zpětně nelze kurzy dohledat. Zápasy mohou kromě výhry a prohry hlavního týmu dopadnout remízou. V rámci našeho algoritmu jsme braly v potaz pouze výhry/prohry. Nicméně dá se říct, že pokud zápas dopadl remízou a naše predikovaná pravděpodobnost výhry hlavního týmu se bude pohybovat v rozmezí 40% - 60%, tak to budeme považovat za správnou predikci.
Výsledky zápasů ve skupinách jsou ve čtyřech tabulkách. Týmy v levém sloupečku bereme jako hlavní týmy. Pod skutečným výsledkem je dopsána naše vypočítaná pravděpodobnost výhry hlavního týmu. Tučně zvýrazněné predikce považujeme za správné.
GROUP A
Ve skupině A z šesti zápasů skončilo pět zápasů remízou. U těchto zápasů jsme predikovaly výhry hlavních týmů s pravděpodobností v rozmezí od 43% do 58%, takže jsme předpokládaly vyrovnané zápasy a to se potvrdilo. U šestého zápasu jsme predikovaly výhru hlavního týmu s pravděpodobností pouze 44%, ale tento tým nakonec vyhrál 2:0.
GROUP B
Ve skupině B jsme dobře predikovaly polovinu zápasů ze šesti. Další zápasy dopadly remízou (my jsme predikovaly výhru/prohru hlavního týmu) nebo opačným výsledkem, než byla naše predikce.
GROUP C
Ve skupině C hrál tým, který není v našem datasetu, takže máme predikce pouze pro tři zápasy. Zde jsme správně predikovaly dva zápasy (EDward Gaming vs. KT Rolster, KT Rolster vs. Team Liquid) a u jednoho zápasu (Edward Gaming vs. Team Liquid) jsme predikovaly výhru hlavního týmu (s pravděpodobností 81%), ale zápas skončil remízou.
GROUP D
Ve skupině D jsme z šesti zápasů správně predikovaly dva zápasy (100 Thieves vs. Invictus Gaming, Fnatic vs. G-Rex). Další dva zápasy jsme predikovaly těsnou výhru a prohru, což nakonec dopadlo přesně obráceně. A u posledních dvou zápasů jsme predikovaly pravděpodobnost vítězství hlavního týmu okolo 70%, ale nakonec jeden dopadl prohrou a jeden remízou.
Následující tabulky ukazují zápasy čtvrtfinále, semifinále a finále, skutečný výsledek zápasů a pravděpodobnost výhry hlavních týmů (první uvedené týmy).
ČTVRTFINÁLE
SEMIFINÁLE
FINÁLE
Ze čtvrtfinálových zápasů jsme správně predikovaly výsledky dvou ze čtyř zápasů. Ze dvou semifinálových zápasů jsme správně predikovaly výsledek jednoho zápasů. A ve finále jsme jako vítěze predikovaly tým, který se umístil na druhém místě.

Zdroj: https://www.facebook.com/lolesports
A jaké je tedy finální shrnutí? Jak byla naše aplikace v predikci úspěšná?
GROUP A
Overall
| |||||
Afreeca Freecs (KR)
|
1 - 1
46%
|
1 - 1
53%
|
2 - 0
44%
|
4 - 2
| |
Flash Wolves (LMS)
|
1 - 1
|
1 - 1
58%
|
1 - 1
52%
|
3 - 3
| |
G2 Esports (EU)
|
1 - 1
|
1 - 1
|
1 - 1
43%
|
3 - 3
| |
Phong Vũ Buffalo (VN)
|
0 - 2
|
1 - 1
|
1 - 1
|
2 - 4
|
Ve skupině A z šesti zápasů skončilo pět zápasů remízou. U těchto zápasů jsme predikovaly výhry hlavních týmů s pravděpodobností v rozmezí od 43% do 58%, takže jsme předpokládaly vyrovnané zápasy a to se potvrdilo. U šestého zápasu jsme predikovaly výhru hlavního týmu s pravděpodobností pouze 44%, ale tento tým nakonec vyhrál 2:0.
GROUP B
Overall
| |||||
Cloud9 (NA)
|
1 - 1
46%
|
1 - 1
30%
|
2 - 0
52%
|
4 - 2
| |
Gen.G (KR)
|
1 - 1
|
0 - 2
29%
|
0 - 2
54%
|
1 - 5
| |
1 - 1
|
2 - 0
|
1 - 1
70%
|
4 - 2
| ||
Team Vitality (EU)
|
0 - 2
|
2 - 0
|
1 - 1
|
3 - 3
|
Ve skupině B jsme dobře predikovaly polovinu zápasů ze šesti. Další zápasy dopadly remízou (my jsme predikovaly výhru/prohru hlavního týmu) nebo opačným výsledkem, než byla naše predikce.
GROUP C
Overall
| |||||
EDward Gaming (CN)
|
1 - 1
53%
|
2 - 0
-
|
1 - 1
81%
|
4 - 2
| |
KT Rolster (KR)
|
1 - 1
|
2 - 0
-
|
2 - 0
78%
|
5 - 1
| |
MAD Team (LMS)
|
0 - 2
|
0 - 2
|
0 - 2
-
|
0 - 6
| |
Team Liquid (NA)
|
1 - 1
|
0 - 2
|
2 - 0
|
3 - 3
|
GROUP D
Overall
| |||||
100 Thieves (NA)
|
0 - 2
52%
|
2 - 0
46%
|
0 - 2
16%
|
2 - 4
| |
Fnatic (EU)
|
2 - 0
|
2 - 0
64%
|
1 - 1
72%
|
5 - 1
| |
G-Rex (LMS)
|
0 - 2
|
0 - 2
|
0 - 2
70%
|
0 - 6
| |
Invictus Gaming (CN)
|
2 - 0
|
1 - 1
|
2 - 0
|
5 - 1
|
Ve skupině D jsme z šesti zápasů správně predikovaly dva zápasy (100 Thieves vs. Invictus Gaming, Fnatic vs. G-Rex). Další dva zápasy jsme predikovaly těsnou výhru a prohru, což nakonec dopadlo přesně obráceně. A u posledních dvou zápasů jsme predikovaly pravděpodobnost vítězství hlavního týmu okolo 70%, ale nakonec jeden dopadl prohrou a jeden remízou.
Následující tabulky ukazují zápasy čtvrtfinále, semifinále a finále, skutečný výsledek zápasů a pravděpodobnost výhry hlavních týmů (první uvedené týmy).
ČTVRTFINÁLE
0 - 3
|
43%
| |
3 - 1
|
39%
| |
2 - 3
|
57%
| |
2 - 3
|
40%
|
SEMIFINÁLE
0 - 3
|
50%
| |
0 - 3
|
32%
|
FINÁLE
0 - 3
|
66%
|
Ze čtvrtfinálových zápasů jsme správně predikovaly výsledky dvou ze čtyř zápasů. Ze dvou semifinálových zápasů jsme správně predikovaly výsledek jednoho zápasů. A ve finále jsme jako vítěze predikovaly tým, který se umístil na druhém místě.
Zdroj: https://www.facebook.com/lolesports
A jaké je tedy finální shrnutí? Jak byla naše aplikace v predikci úspěšná?
Z celkových 28 zápasů jsme správně predikovaly výsledky 15 zápasů.
Bohužel, jak jsme již zmiňovaly, nemáme kurzy sázkových kanceláří na dané zápasy a proto nemůžeme naše predikce porovnat s predikcemi sázkových kanceláří. Čistě teoreticky dle kurzů mohli být favorité zápasů stejní jako dle našich predikcí, ale jak se to stává v každém sportu (pokud budeme tuto online počítačovou hru považovat za sport :) ), ne vždycky vyhraje favorit. Ve výsledcích zápasů mohou hrát hru další faktory - stres a tlak na úspěch (mistrovství světa je přece jen celkem dost velká událost, která se hraje v zaplněné hale), jet lag (cestování přes půlku světa do Jižní Korei může na člověku zanechat nějaké stopy), aktuální forma a psychické rozpoložení jedinců. A toto jsou všechno faktory, které není možné zahrnout do našeho algoritmu.
Co by se dalo v rámci projektu dělat dál? Kam se dá projekt ještě posunout?
- Místo command line aplikace vytvořit webovou aplikaci, která by mohla ještě ukazovat další parametry a informace.
- Dataset neustále aktualizovat o nové a nové výsledky a statistiky.
- Dataset rozšířit o další období.
- Ještě hlouběji analyzovat výsledky pro konkrétní hráče. Kdo je například “tahounem” týmu a bez koho se neobejde vyhraný zápas.
- Náš kód s binární logistickou regresí obohatit o další možné regrese, aby byl výsledek ještě přesnější.
- Porovnat naše predikce s realitou a kurzy sázkových kanceláří z dlouhodobého hlediska.
- Aplikovat predikce i na jiné hry nebo sporty.
- Prodat to sazkovce :D
Také moc děkujeme Czechitas za příležitost být v takovém super kurzu s ještě skvělejšími účastnicemi, lektorům za to kvantum informací, které nám každou lekci předávali a veškerý čas, kterým nám věnovali a partnerům za perfektně připravené exkurze.
Zdroje:
- www.google.cz
- https://stackoverflow.com/
- https://lol.gamepedia.com/2018_Season_World_Championship
- https://www.lolesports.com/en_US/
- http://matpat.wikia.com/wiki/League_of_Legends
- http://gol.gg/esports/home/
- https://www.dexerto.com/league-of-legends/the-groups-have-been-drawn-for-the-2018-league-of-legends-world-championship-171622
- https://www.facebook.com/lolesports
- http://www.memesboy.com/
Komentáře
Okomentovat